使用 AWS Lambda 设置基本的执行运行程序
在本指南中,您将部署一个新的 "AWS Lambda 函数",该函数将订阅 "runs "主题,并根据 Port 中设置的调用执行正确的操作。
先决条件
- AWS CLI 已安装并配置到所需的 AWS 帐户;
- Port API
CLIENT_ID和CLIENT_SECRET; - Port 提供的 Kafka 主题连接凭证:
KAFKA_BROKERS=b-1-public.publicclusterprod.t9rw6w.c1.kafka.eu-west-1.amazonaws.com:9196,b-2-public.publicclusterprod.t9rw6w.c1.kafka.eu-west-1.amazonaws.com:9196,b-3-public.publicclusterprod.t9rw6w.c1.kafka.eu-west-1.amazonaws.com:9196
KAFKA_RUNS_TOPIC=YOUR_ORG_ID.runs
KAFKA_AUTHENTICATION_MECHANISM=scram-sha-512
KAFKA_ENABLE_SSL=true
KAFKA_USERNAME=YOUR_KAFKA_USERNAME
KAFKA_PASSWORD=YOUR_KAFKA_PASSWORD
KAFKA_CONSUMER_GROUP_NAME=YOUR_KAFKA_CONSUMER_GROUP
为了快速上手,您可以随时查看code repository 以了解示例。
在本示例中,与 Port 的交互主要通过应用程序接口进行,但也可以通过网络用户界面进行。
场景
让我们来了解一下 Port 的执行功能。 为此,首先创建一个新的 Lambda 函数,在 AWS 云环境中部署一个新的虚拟机
创建虚拟机蓝图
让我们配置一个 "VM "蓝图,它的基本结构是
{
"identifier": "vm",
"title": "VM",
"icon": "Server",
"schema": {
"properties": {
"region": {
"title": "Region",
"type": "string",
"description": "Region of the VM"
},
"cpu_cores": {
"title": "CPU Cores",
"type": "number",
"description": "Number of allocated CPU cores"
},
"memory_size": {
"title": "Memory Size ",
"type": "number",
"description": "Amount of allocated memory (GB)"
},
"storage_size": {
"title": "Storage Size",
"type": "number",
"description": "Amount of allocated storage (GB)"
},
"deployed": {
"title": "Deploy Status",
"type": "string",
"description": "The deployment status of this VM"
}
},
"required": []
},
"calculationProperties": {}
}
下面是创建该蓝图的 python 代码(请记住插入您的 CLIENT_ID 和 CLIENT_SECRET 以获取访问令牌)。
Click here to see the code
import requests
CLIENT_ID = 'YOUR_CLIENT_ID'
CLIENT_SECRET = 'YOUR_CLIENT_SECRET'
API_URL = 'https://api.getport.io/v1'
credentials = {'clientId': CLIENT_ID, 'clientSecret': CLIENT_SECRET}
token_response = requests.post(f'{API_URL}/auth/access_token', json=credentials)
access_token = token_response.json()['accessToken']
headers = {
'Authorization': f'Bearer {access_token}'
}
blueprint = {
"identifier": "vm",
"title": "VM",
"icon": "Server",
"schema": {
"properties": {
"region": {
"title": "Region",
"type": "string",
"description": "Region of the VM"
},
"cpu_cores": {
"title": "CPU Cores",
"type": "number",
"description": "Number of allocated CPU cores"
},
"memory_size": {
"title": "Memory Size ",
"type": "number",
"description": "Amount of allocated memory (GB)"
},
"storage_size": {
"title": "Storage Size",
"type": "number",
"description": "Amount of allocated storage (GB)"
},
"deployed": {
"title": "Deploy Status",
"type": "string",
"description": "What is the deployment status of this VM"
}
},
"required": []
},
"calculationProperties": {},
}
response = requests.post(f'{API_URL}/blueprints', json=blueprint, headers=headers)
print(response.json())
创建虚拟机 CREATE 操作
现在,让我们配置一个 Self-Service Action。 您将添加一个 CREATE 操作,开发人员每次创建新的虚拟机实体时都会触发该操作,Self-Service Action 将触发您的 Lambda。
以下是操作 JSON:
{
"identifier": "create_vm",
"title": "Create VM",
"icon": "Server",
"description": "Create a new VM in cloud provider infrastructure",
"trigger": "CREATE",
"invocationMethod": { "type": "KAFKA" },
"userInputs": {
"properties": {
"title": {
"type": "string",
"title": "Title of the new VM"
},
"cpu": {
"type": "number",
"title": "Number of CPU cores"
},
"memory": {
"type": "number",
"title": "Size of memory"
},
"storage": {
"type": "number",
"title": "Size of storage"
},
"region": {
"type": "string",
"title": "Deployment region",
"enum": ["eu-west-1", "eu-west-2", "us-west-1", "us-east-1"]
}
},
"required": ["cpu", "memory", "storage", "region"]
}
}
下面是创建此操作的 python 代码(请记住插入您的 CLIENT_ID 和 CLIENT_SECRET 以获取访问令牌)。
vm 蓝图标识符是如何被用于以将操作添加到新蓝图的Click here to see code
import requests
CLIENT_ID = 'YOUR_CLIENT_ID'
CLIENT_SECRET = 'YOUR_CLIENT_SECRET'
API_URL = 'https://api.getport.io/v1'
credentials = {'clientId': CLIENT_ID, 'clientSecret': CLIENT_SECRET}
token_response = requests.post(f'{API_URL}/auth/access_token', json=credentials)
access_token = token_response.json()['accessToken']
headers = {
'Authorization': f'Bearer {access_token}'
}
blueprint_identifier = 'vm'
action = {
'identifier': 'create_vm',
'title': 'Create VM',
'icon': 'Server',
'description': 'Create a new VM in cloud provider infrastructure',
'trigger': 'CREATE',
'invocationMethod': { 'type': 'KAFKA' },
'userInputs': {
'properties': {
'title': {
'type': 'string',
'title': 'Title of the new VM'
},
'cpu': {
'type': 'number',
'title': 'Number of CPU cores'
},
'memory': {
'type': 'number',
'title': 'Size of memory'
},
'storage': {
'type': 'number',
'title': 'Size of storage'
},
'region': {
'type': 'string',
'title': 'Deployment region',
'enum': ['eu-west-1', 'eu-west-2', 'us-west-1', 'us-east-1']
}
},
'required': [
'cpu', 'memory', 'storage', 'region'
]
}
}
response = requests.post(f'{API_URL}/blueprints/{blueprint_identifier}/actions', json=action, headers=headers)
print(response.json())
自助服务操作配置完成后,就可以开始调用了。
自助服务操作需要一个运行程序,它将接收调用消息,并根据 Provider 提供的数据执行一些逻辑。
设置 AWS 资源
在本示例中,部署的 AWS Lambda 函数将用 python 编写。
**AWS 设置需要以下资源: **
- 存储在 Secrets Manager 中的带有 Kafka 身份验证凭据的secret。
- 可访问新secret的 AWS Lambda 执行角色。
- 一个 AWS Lambda 层,用于我们的额外 python 库。
- 将 AWS Lambda 配置为示例 python 代码、代码层和您创建的执行角色。配置 Kafka 触发器
为 Lambda 创建secret
Lambda 函数将使用在 AWS Secret Manager 中配置的 "secret "来与 Port 提供的个人 Kafka 主题进行身份验证,让我们继续在 AWS CLI 中创建该 secret:
# Remember to replace YOUR_KAFKA_USERNAME and YOUR_KAFKA_PASSWORD with the real username and password provided to you by Port
# You can change the secret name to any name that works for you
aws secretsmanager create-secret --name "PortKafkaAuthCredentials" --secret-string '{"username":"YOUR_KAFKA_USERNAME", "password":"YOUR_KAFKA_PASSWORD"}'
您应该会看到类似下面的 Output:
{
"ARN": "arn:aws:secretsmanager:eu-west-1:1111111111:secret:PortKafkaAuthCredentials-aaaaaa",
"Name": "PortKafkaAuthCredentials",
"VersionId": "aaaaa00a-00aa-0000-00a0-00000aa00a0a"
}
ARN 确保保存 ARN 值,您将需要它来为 Lambda 函数创建一个执行角色,该角色可以访问新创建的 secret。创建执行角色
在部署 Lambda 函数之前,它需要一个可以访问您创建的 Kafka 用户名和密码secret的execution role 。让我们创建一个具有assumeRole权限和cloudWatch基本权限的basic execution role
aws iam create-role --role-name lambda-port-execution-role --assume-role-policy-document '{"Version": "2012-10-17","Statement": [{ "Effect": "Allow", "Principal": {"Service": "lambda.amazonaws.com"}, "Action": "sts:AssumeRole"}]}'
您应该会看到类似下面的 Output:
{
"Role": {
"Path": "/",
"RoleName": "lambda-port-execution-role",
"RoleId": "AROAQFOXMPL6TZ6ITKWND",
"Arn": "arn:aws:iam::123456789012:role/lambda-port-execution-role",
"CreateDate": "2020-01-17T23:19:12Z",
"AssumeRolePolicyDocument": {
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": [
"arn:aws:secretsmanager:eu-west-1:1111111111:secret:PortKafkaAuthCredentials-aaaaaa"
]
},
{
"Effect": "Allow",
"Action": "secretsmanager:ListSecrets",
"Resource": "*"
}
]
}
}
}
ARN 再次,确保保存 Arn 值,您将在部署 Lambda 函数时使用它让我们用以下命令为该角色附加基本的 Lambda 执行权限:
aws iam attach-role-policy --role-name lambda-port-execution-role --policy-arn arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
现在,让我们添加以下策略(更多信息请参阅AWS document ) ,我们将创建一个名为 execution-policy.json 的文件,并粘贴以下内容:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"secretsmanager:GetResourcePolicy",
"secretsmanager:GetSecretValue",
"secretsmanager:DescribeSecret",
"secretsmanager:ListSecretVersionIds"
],
"Resource": [
"arn:aws:secretsmanager:eu-west-1:1111111111:secret:PortKafkaAuthCredentials-aaaaaa"
]
},
{
"Effect": "Allow",
"Action": "secretsmanager:ListSecrets",
"Resource": "*"
}
]
}
现在让我们更新执行角色(假设 execution-policy.json 文件与运行命令的终端位于同一目录):
aws iam put-role-policy --role-name lambda-port-execution-role --policy-name managed-kafka-secret-access-policy --policy-document file://execution-policy.json
创建 AWS Lambda 层
现在,让我们创建一个Lambda Layer ,其中将包含 Lambda 函数将使用的额外库。
Lambda 只需要requests 库,但下面的示例还包括一些日志输出的jsonpickle ,以使 Lambda 日志更加冗长,在开始修改代码时更容易理解。
现在,让我们运行所有命令来创建层 zip 并将其部署到 AWS(请务必指定希望层和 lambda 可用的区域):
# Create layer directory and specify requests as a required library
mkdir lambda_layer
cd lambda_layer
echo requests==2.28.1 > requirements.txt
echo jsonpickle==2.2.0 >> requirements.txt
# Create layer based on requirements.txt in python/ directory
pip install -r requirements.txt --platform manylinux2014_x86_64 --target ./python --only-binary=:all:
# Create a zip of the layer
zip -r layer.zip python
# Upload a new layer version to AWS
aws lambda publish-layer-version --layer-name lambda_port_execution_package_layer --description "Python pacakges layer for lambda Port execution example" --compatible-runtimes python3.6 python3.7 python3.8 python3.9 --zip-file fileb://layer.zip --region eu-west-1
您应该会看到类似下面的 Output:
{
"Content": {
"Location": "https://awslambda-eu-west-1-layers.s3.eu-west-1.amazonaws.com/snapshots/123456789012/my-layer-4aaa2fbb-ff77-4b0a-ad92-5b78a716a96a?versionId=27iWyA73cCAYqyH...",
"CodeSha256": "tv9jJO+rPbXUUXuRKi7CwHzKtLDkDRJLB3cC3Z/ouXo=",
"CodeSize": 169
},
"LayerArn": "arn:aws:lambda:eu-west-1:123456789012:layer:lambda_port_execution_package_layer",
"LayerVersionArn": "arn:aws:lambda:eu-west-1:123456789012:layer:lambda_port_execution_package_layer:1",
"Description": "Python pacakges layer for lambda Port execution example",
"CreatedDate": "2018-11-14T23:03:52.894+0000",
"Version": 1,
"CompatibleArchitectures": ["x86_64"],
"LicenseInfo": "MIT",
"CompatibleRuntimes": ["python3.6", "python3.7", "python3.8", "python3.9"]
}
LayerVersionArn 值,您将用它来部署您的 Lambda 函数创建 Lambda 函数
现在,您可以创建 Lambda 函数,初始函数非常基本,并在实际执行运行逻辑的位置有特定注释。
Click here to see the function code
# file: lambda_function.py
# lambda entrypoint: lambda_handler
import base64
import os
import logging
import jsonpickle
import json
import requests
import traceback
logger = logging.getLogger()
logger.setLevel(logging.INFO)
CLIENT_ID = os.environ['PORT_CLIENT_ID']
CLIENT_SECRET = os.environ['PORT_CLIENT_SECRET']
CREATE_TRIGGER = 'CREATE'
API_URL = 'https://api.getport.io/v1'
def convert_status_code_to_run_status(status_code: int):
if 200 <= status_code < 300:
return "SUCCESS"
if status_code >= 400:
return "FAILURE"
return "IN_PROGRESS"
def get_port_api_token():
'''
Get a Port API access token
This function uses a global ``CLIENT_ID`` and ``CLIENT_SECRET``
'''
credentials = {'clientId': CLIENT_ID, 'clientSecret': CLIENT_SECRET}
token_response = requests.post(f'{API_URL}/auth/access_token', json=credentials)
access_token = token_response.json()['accessToken']
return access_token
def report_to_port(run_id: str ,entity_props: dict):
'''
Reports to Port on a new entity based on provided ``entity_props``
'''
logger.info('Fetching token')
token = get_port_api_token()
blueprint_identifier = 'vm'
headers = {
'Authorization': f'Bearer {token}'
}
params = {
'run_id': run_id
}
entity = {
'identifier': entity_props['title'].replace(' ', '-').lower(),
'title': entity_props['title'],
'properties': {
'cpu_cores': entity_props['cpu'],
'memory_size': entity_props['memory'],
'storage_size': entity_props['storage'],
'region': entity_props['region'],
'deployed': 'Deploying'
}
}
logger.info('Creating entity:')
logger.info(json.dumps(entity))
response = requests.post(f'{API_URL}/blueprints/{blueprint_identifier}/entities', json=entity, headers=headers, params=params)
logger.info(response.status_code)
logger.info(json.dumps(response.json()))
return response.status_code
def report_action_status(run_id: str, status: str):
'''
Reports to Port on the status of an action run ``entity_props``
'''
logger.info('Fetching token')
token = get_port_api_token()
headers = {
'Authorization': f'Bearer {token}'
}
body = {
"status": status,
"message": {
"message": f"The action status is {status}"
}
}
logger.info(f'Reporting action {run_id} status:')
logger.info(json.dumps(body))
response = requests.patch(f'{API_URL}/actions/runs/{run_id}', json=body, headers=headers)
logger.info(response.status_code)
logger.info(json.dumps(response.json()))
return response.status_code
def lambda_handler(event, context):
'''
Receives an event from AWS, if configured with a Kafka Trigger, the event includes an array of base64 encoded messages from the different topic partitions
'''
logger.info('## ENVIRONMENT VARIABLES\r' + jsonpickle.encode(dict(**os.environ)))
logger.info('## EVENT\r' + jsonpickle.encode(event))
logger.info('## CONTEXT\r' + jsonpickle.encode(context))
for messages in event['records'].values():
for encoded_message in messages:
try:
message_json_string = base64.b64decode(encoded_message['value']).decode('utf-8')
logger.info('Received message:')
logger.info(message_json_string)
message = json.loads(message_json_string)
run_id = message['context']['runId']
# "message" includes one execution invocation object
# You can use the message object as shown here to filter the handling of different actions you configured in Port
action_type = message['payload']['action']['trigger']
if action_type != CREATE_TRIGGER:
return {'message': 'Message not directed to our service'}
# # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# Your handler code for the action execution comes here #
# # # # # # # # # # # # # # # # # # # # # # # # # # # # #
# All of the input fields you specified in the action invocation are available under message['payload']['properties']
# For this example, we are simply invoking a simple reporter function which will send data about the new entity to Port
status_code = report_to_port(run_id, message['payload']['properties'])
report_action_status(run_id, convert_status_code_to_run_status(status_code))
except Exception as e:
traceback.print_exc()
logger.warn(f'Error: {e}')
return {"message": "ok"}
if __name__ == "__main__":
pass
部署 Lambda 函数
为了部署 Lambda 函数,请在终端运行以下命令(注意注释中需要将 Lambda 代码粘贴到新文件的地方):
ROLE_ARN 替换为为 Lambda 创建执行角色时作为 Output 收到的 ARN。mkdir port_execution_lambda
cd port_execution_lambda
touch lambda_function.py
# Open lambda_function.py in your favorite editor or IDE and paste
# in the python code written above
# Once the code is in, we can package the lambda and deploy it
zip -FSr function.zip lambda_function.py
# Now let's deploy the Lambda to AWS
aws lambda create-function --function-name port-execution-lambda \
--zip-file fileb://function.zip --handler lambda_function.lambda_handler --runtime python3.9 \
--role ROLE_ARN --timeout 30
您应该会看到类似下面的 Output:
{
"FunctionName": "port-execution-lambda",
"FunctionArn": "arn:aws:lambda:us-east-2:123456789012:function:port-execution-lambda",
"Runtime": "python3.9",
"Role": "arn:aws:iam::123456789012:role/lambda-port-execution-role",
"Handler": "lambda_function.lambda_handler",
"CodeSha256": "FpFMvUhayLkOoVBpNuNiIVML/tuGv2iJQ7t0yWVTU8c=",
"Version": "$LATEST",
"TracingConfig": {
"Mode": "PassThrough"
},
"RevisionId": "88ebe1e1-bfdf-4dc3-84de-3017268fa1ff",
...
}
您只需几步就能实现完整的执行流程!
把所有东西放在一起
只剩下几个步骤了:
- 在 Lambda 函数中添加代码层
- 将 Port
CLIENT_ID和CLIENT_SECRET作为环境变量添加到 Lambda 中 - 添加 Kafka 触发器
要添加图层,只需运行一个简单的 CLI 命令即可:
# Be sure to replace the LAYER_VERSION_ARN with the value you saved
# from the layer creation output
aws lambda update-function-configuration --function-name port-execution-lambda \
--layers LAYER_VERSION_ARN
您应该会看到一个 Output,显示现在 Lambda 的 Layers 数组包含了我们的层
现在添加 client_id 和 secret 变量:
# Be sure to replace YOUR_CLIENT_ID and YOUR_CLIENT_SECRET with real values
aws lambda update-function-configuration --function-name port-execution-lambda --environment "Variables={PORT_CLIENT_ID=YOUR_CLIENT_ID,PORT_CLIENT_SECRET=YOUR_CLIENT_SECRET}" --query "Environment"
在命令输出中,你应该能看到为 Lambda 函数配置的所有 secrets。
environment.json)并运行以下命令会更简单:aws lambda update-function-configuration --function-name port-execution-lambda --environment file://environment.json --query "Environment"
添加 Kafka 触发器的时间到了
# Remember to replace YOUR_ORG_ID, SECRET_ARN, and YOUR_KAFKA_CONSUMER_GROUP
aws lambda create-event-source-mapping --topics YOUR_ORG_ID.runs --source-access-configuration Type=SASL_SCRAM_512_AUTH,URI=SECRET_ARN \
--function-name port-execution-lambda \
--batch-size 1 --starting-position LATEST \
--self-managed-kafka-event-source-config '{"ConsumerGroupId":"YOUR_KAFKA_CONSUMER_GROUP"}' \
--self-managed-event-source '{"Endpoints":{"KAFKA_BOOTSTRAP_SERVERS":["b-1-public.publicclusterprod.t9rw6w.c1.kafka.eu-west-1.amazonaws.com:9196", "b-2-public.publicclusterprod.t9rw6w.c1.kafka.eu-west-1.amazonaws.com:9196", "b-3-public.publicclusterprod.t9rw6w.c1.kafka.eu-west-1.amazonaws.com:9196"]}}'
触发action
现在,Lambda 已配置了 Kafka 触发器,每次操作调用都会在触发器中指定的专用 Kafka 主题中生成一条新消息。 该消息将与操作调用所需的所有输入数据一起发送到您部署的 Lambda 函数。
有关托管 Apache Kafka 触发器数据格式的更多信息,请参阅AWS docs 。你在 lambda_handler 函数中编写的代码已经对所有新消息进行过解析、解码并转换为 python 字典,以方便使用。
现在让我们使用 Port API 引用自助服务操作
Click here to see the API call code
import requests
CLIENT_ID = 'YOUR_CLIENT_ID'
CLIENT_SECRET = 'YOUR_CLIENT_SECRET'
API_URL = 'https://api.getport.io/v1'
credentials = {'clientId': CLIENT_ID, 'clientSecret': CLIENT_SECRET}
token_response = requests.post(f'{API_URL}/auth/access_token', json=credentials)
access_token = token_response.json()['accessToken']
headers = {
'Authorization': f'Bearer {access_token}'
}
blueprint_identifier = 'vm'
action_identifier = 'create_vm'
action_run = {
'properties': {
'title': 'Backend Prod VM',
'cpu': 2,
'memory': 4,
'storage': 50,
'region': 'eu-west-1'
}
}
response = requests.post(f'{API_URL}/blueprints/{blueprint_identifier}/actions/{action_identifier}/runs', json=action_run, headers=headers)
print(response.json())
这将向 Kafka 主题发送一条信息。
现在,Lambda 函数的 CloudWatch 日志(可在 AWS 控制台中通过 Lambda→functions→port-execution-lambda→Monitor→Logs→View logs 在 CloudWatch 中访问)将显示 Lambda 函数的最新执行日志。 其中还包括实际收到的消息,以及是否已成功向 Port 报告此新虚拟机实体:
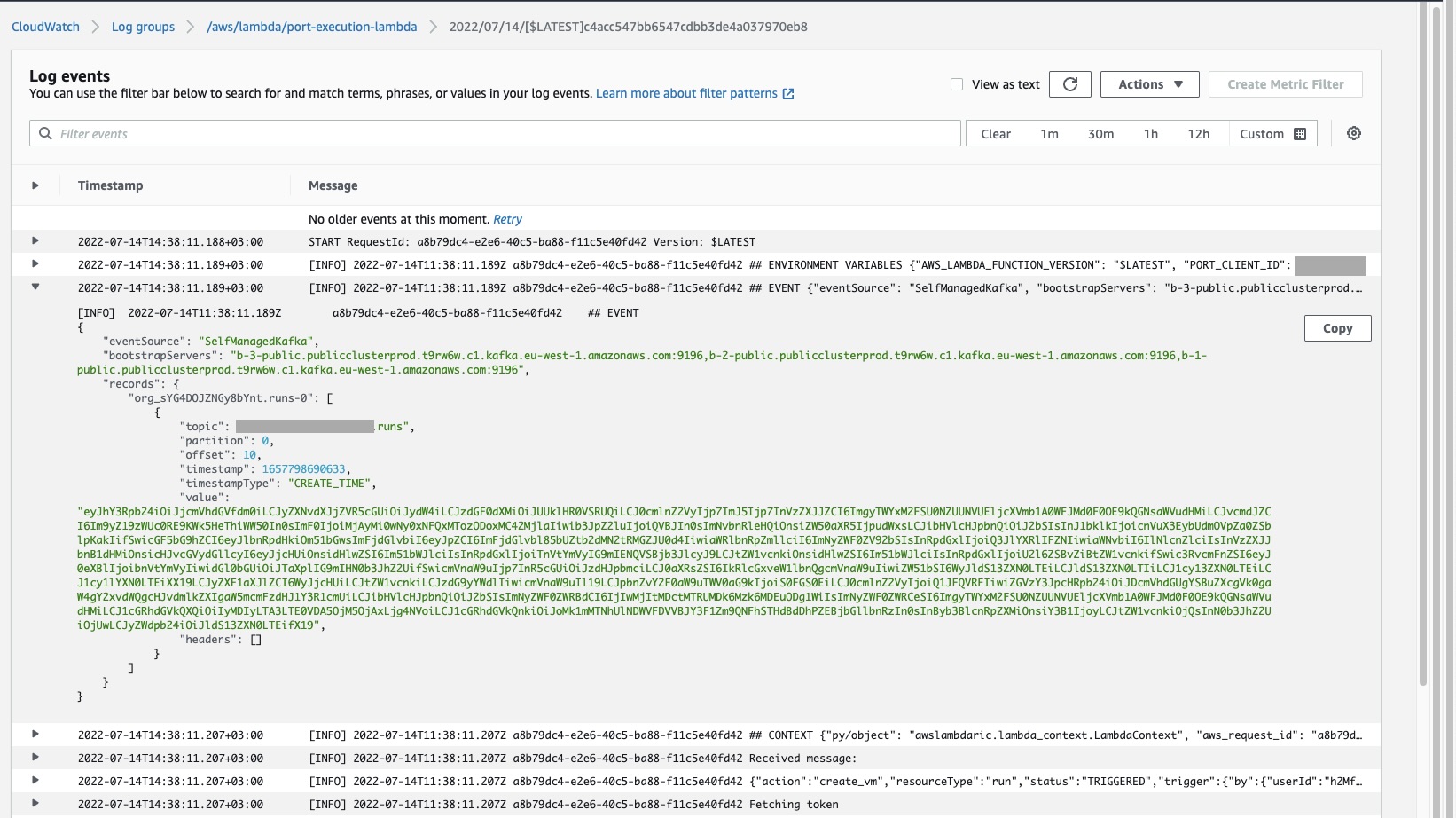
下面是 Kafka 消息中从 Port 接收到的请求有效载荷示例:
{
"action": "create_vm",
"resourceType": "run",
"status": "TRIGGERED",
"trigger": {
"by": {
"userId": "h2Mf13aRSCYQCUPIcqufoP4XRLwAt8Od@clients",
"orgId": "org_sYG4DOJZNGy8bYnt",
"user": {
"email": "[email protected]",
"firstName": "test",
"lastName": "test",
"id": "auth0|638879fa62c686d381b36ecb"
}
},
"at": "2022-07-14T11:38:10.629Z",
"origin": "API"
},
"context": {
"entity": null,
"blueprint": "vm",
"runId": "run_q2mGf9ZYkFRnZJjB"
},
"payload": {
"entity": null,
"action": {
"id": "action_9mFmogL7kQ0fISGx",
"identifier": "create_vm",
"title": "Create VM",
"icon": "Server",
"userInputs": {
"properties": {
"cpu": {
"type": "number",
"title": "Number of CPU cores"
},
"memory": {
"type": "number",
"title": "Size of memory"
},
"storage": {
"type": "number",
"title": "Size of storage"
},
"region": {
"type": "string",
"title": "Deployment region",
"enum": ["eu-west-1", "eu-west-2", "us-west-1", "us-east-1"]
}
},
"required": ["cpu", "memory", "storage", "region"]
},
"invocationMethod": { "type": "KAFKA" },
"trigger": "CREATE",
"description": "Create a new VM in cloud provider infrastructure",
"blueprint": "vm",
"createdAt": "2022-07-14T09:39:01.885Z",
"createdBy": "h2Mf13aRSCYQCUPIcqufoP4XRLwAt8Od@clients",
"updatedAt": "2022-07-14T09:39:01.885Z",
"updatedBy": "h2Mf13aRSCYQCUPIcqufoP4XRLwAt8Od@clients"
},
"properties": {
"cpu": 2,
"memory": 4,
"storage": 50,
"region": "eu-west-1"
}
}
}
除了在 Cloudwatch 中看到消息主题外,Lambda 函数代码还会根据 Provider 的输入在 Port 中创建一个新的虚拟机实体。
当操作完成后,它会将操作运行标记为成功�。 这样,你的开发人员就可以知道新虚拟机的配置已经成功完成。
下一步
这是一个非常基本的示例,说明如何对执行 CREATE 操作作出反应。 我们留下了占位符代码,供您插入适合自己基础架构的自定义逻辑。
现在您有了执行运行程序,也许可以尝试探索我们的Change Log runner ,以便对软件目录中的变化做出反应。